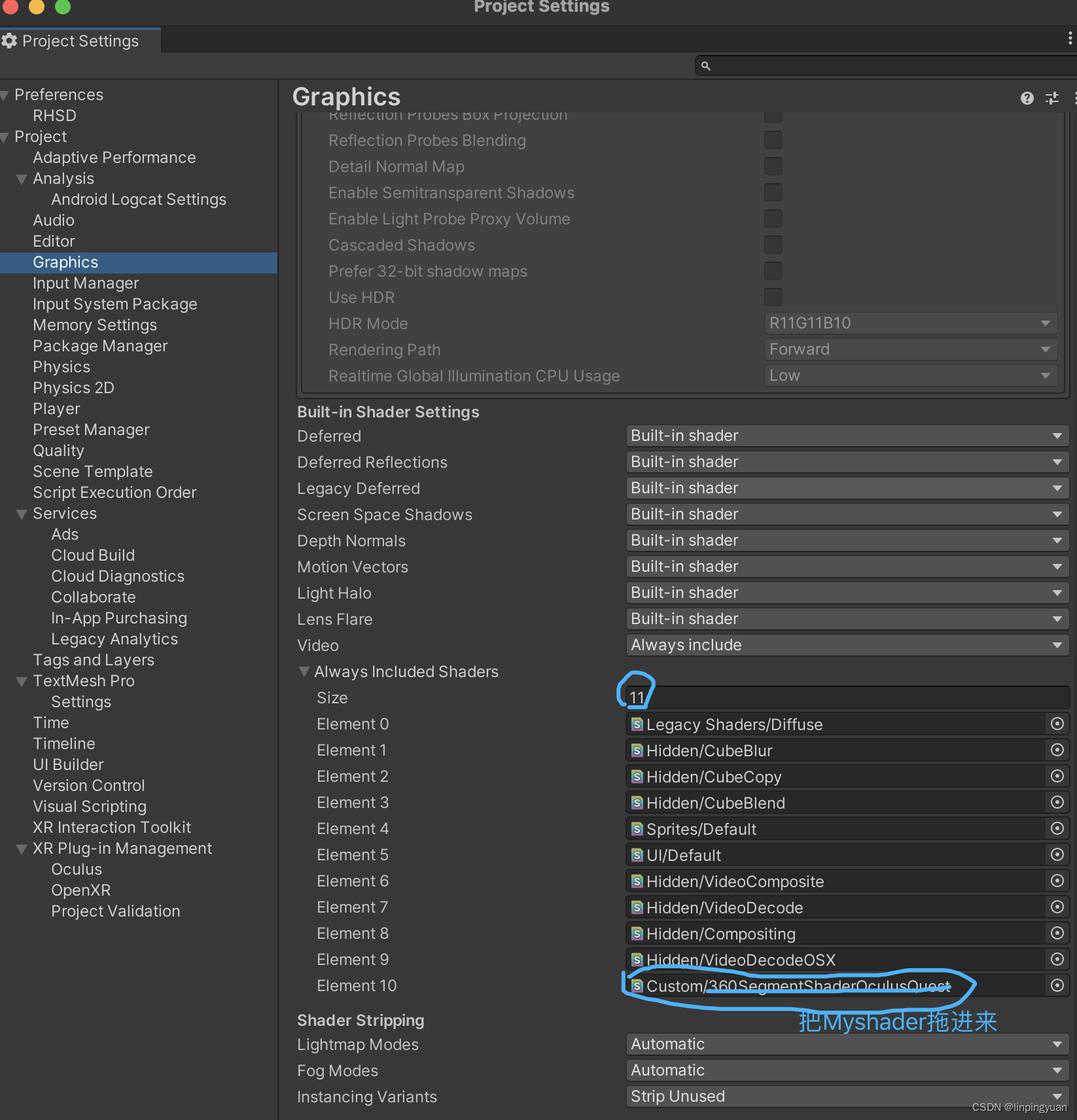
非结构化数据
在处理非结构化数据时,文本切分策略的选择至关重要,以保持信息完整性和提高检索效率。以下是一些有效的切分方法:
- 固定长度切分:将文本按照固定的字数或词数进行切分,例如每个文档切分成300个字或300个词的块。但这种方法可能会在句子或语义重要部分的中间切断,影响理解和检索效果。
- 基于句子的切分:在这种策略中,文本被分割成多个部分,这些部分是根据句子的自然边界来确定的。这意味着我们利用自然语言处理技术来识别句子的结尾,比如句号、问号等标点符号,然后在这些点上进行切分。这种方式有助于维护语义的连贯性,但可能会导致各个块的长度参差不齐,这可能会使得检索和匹配过程变得更加复杂。
- 滑动窗口(Sliding Window):在这种切分技术中,文本被划分为一系列重叠的部分,通过使用一个滑动窗口来完成。例如,我们可以设定一个窗口大小为300个词,并且每次滑动30个词。这种方法能够有效减少在固定长度切分或基于句子边界切分时可能发生的信息丢失问题。
- 基于主题或段落的切分:这种先进的切分技术利用了文本的固有结构,如段落或主题转换点,来创建文本块。通过这种方式,我们可以识别并按照段落或文本中的主题变化来进行切分,从而确保了高度的语义连续性。这种方法特别适用于那些结构较为清晰的文本,比如学术论文和正式报告。
- 基于语义相似度的切分:利用机器学习模型,如BERT或其他语言模型,可以评估句子或段落之间的语义相似性,并在相似性低于设定阈值时进行文本切分。这种方法旨在保持文本的语义连贯性的同时,提升检索效率。
结构化数据
在处理结构化数据时,为了提高效率和便于管理,我们可以采用多种切分策略:
- 基于行的切分:在处理结构化数据时,最简单的切分方法是根据行数来分割。例如,对于大型CSV文件,可以将其数据分成每组300行的多个块,每个块包含相应数量的数据行。
- 基于列的切分:在某些场景下,特别是当某些列包含了大量独特的数据(例如时间序列数据或高度独立的特征)时,可以选择按照列来分割数据集。
- 基于值的切分(Hashing/Sharding):这种技术包括根据一个或多个字段的值来切分数据,这在数据库分区中很常见。例如,可以根据用户ID的哈希值将数据行分配到不同的服务器或文件中,这样做可以平衡工作负载并提升查询效率。
- 基于查询优化的切分:了解常见的查询模式后,我们可以据此优化数据切分策略。例如,如果频繁地对特定日期范围内的数据进行查询,那么按照日期字段对数据进行预分区将极大提升查询效率。
- 使用索引和分区技术:在数据库管理中,为了提高数据存储和检索的效率,我们通常会创建索引和进行数据分区。索引能够加速数据的定位,而分区则将数据物理分布在不同的区域,以便根据查询需求快速提取相关数据块。
- 基于业务逻辑的切分:在某些场景下,数据的分割也可以根据业务需求来进行。比如,客户数据可以根据地理位置来划分,而金融数据则可以根据不同的产品或服务类别来分割。